消息隊列服務(wù)Kafka揭秘 痛點、優(yōu)勢與適用場景
隨著企業(yè)數(shù)據(jù)規(guī)模和系統(tǒng)復雜度的不斷攀升,信息集成與異步通信成為系統(tǒng)架構(gòu)中的核心挑戰(zhàn)。Apache Kafka作為一款分布式流處理平臺和消息隊列服務(wù),憑借其高吞吐、可擴展和持久化的特性,在眾多領(lǐng)域脫穎而出。本文將深入解析Kafka的核心原理,剖析其使用中的痛點與獨特優(yōu)勢,并探討其典型的適用場景。
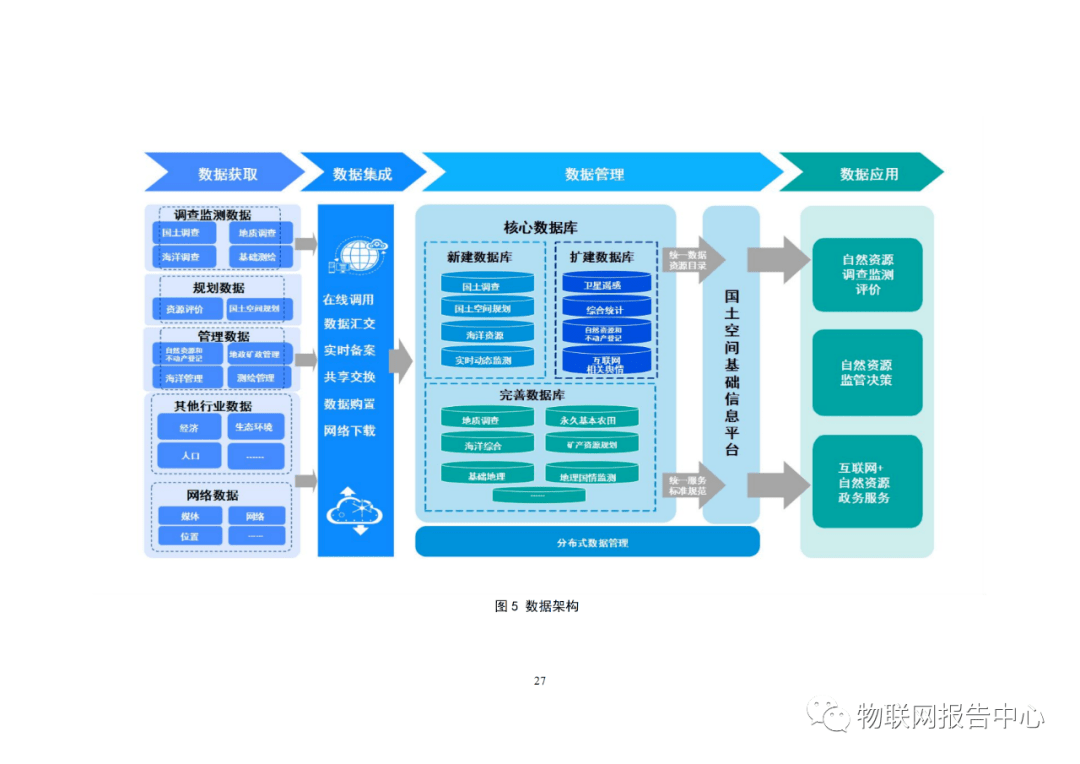
Kafka的核心架構(gòu)與工作原理
Kafka本質(zhì)上是一個基于發(fā)布/訂閱模式的分布式消息系統(tǒng)。其核心架構(gòu)主要由以下幾個組件構(gòu)成:
- Producer(生產(chǎn)者):負責將消息發(fā)布(推送)到指定的Topic(主題)。
- Consumer(消費者):訂閱一個或多個Topic,并從中拉取(pull)消息進行處理。
- Broker(代理服務(wù)器):Kafka集群中的單個節(jié)點,負責消息的存儲和轉(zhuǎn)發(fā)。
- Topic(主題):消息的邏輯分類,生產(chǎn)者將消息發(fā)送到特定Topic,消費者訂閱感興趣的Topic。
- Partition(分區(qū)):每個Topic可以被分為多個分區(qū),分布在不同的Broker上。分區(qū)是實現(xiàn)水平擴展和并行處理的基礎(chǔ)。
- ZooKeeper:在早期版本中,Kafka依賴ZooKeeper進行元數(shù)據(jù)管理和集群協(xié)調(diào)(如Broker注冊、Leader選舉)。新版本正逐步移除對ZooKeeper的依賴(KIP-500)。
其工作流程是:Producer將消息發(fā)送到指定Topic的某個分區(qū);消息被順序、持久化地存儲在分區(qū)日志中;Consumer通過維護自身的偏移量(offset)來跟蹤消費進度,從而可以靈活地重放歷史數(shù)據(jù)。
使用Kafka可能遇到的痛點
盡管Kafka功能強大,但在實際應(yīng)用中,開發(fā)與運維團隊也面臨一些挑戰(zhàn):
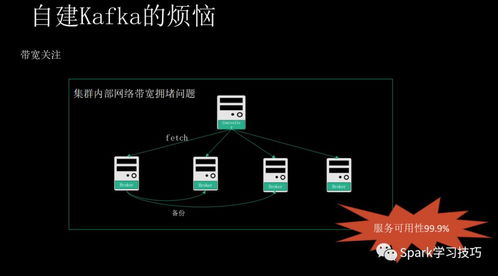
- 運維復雜度高:Kafka集群的部署、監(jiān)控、調(diào)優(yōu)和擴容需要專業(yè)的知識和經(jīng)驗。涉及Broker、ZooKeeper、網(wǎng)絡(luò)、磁盤I/O等多方面的配置與管理。
- 概念與配置繁多:對于初學者,分區(qū)、副本、ISR、ACK機制、日志保留策略等概念需要時間理解。不恰當?shù)呐渲茫ㄈ?code>acks、
retries、compression.type)可能直接影響系統(tǒng)的可靠性與性能。 - 客戶端生態(tài)與版本兼容性:Kafka擁有多語言客戶端,但其成熟度不一。服務(wù)端與客戶端版本的兼容性問題有時會帶來意想不到的麻煩。
- “Exactly-Once”語義的實現(xiàn)復雜度:雖然Kafka提供了事務(wù)API以實現(xiàn)精確一次處理語義,但其實現(xiàn)相對復雜,對應(yīng)用設(shè)計和性能有一定影響。
- 資源消耗:為了達到高性能,Kafka會充分利用頁緩存(Page Cache),對內(nèi)存需求較高。其持久化機制意味著需要提供高性能的磁盤存儲。
- 不適合小規(guī)模場景:對于非常簡單的、低吞吐量的應(yīng)用,引入Kafka可能會帶來不必要的架構(gòu)復雜度和運維負擔。
Kafka的顯著優(yōu)勢
面對上述痛點,Kafka之所以仍被廣泛采用,歸功于其不可替代的優(yōu)勢:
- 高吞吐量與低延遲:通過順序I/O、零拷貝(Zero-Copy)和批處理等技術(shù),Kafka能夠輕松處理每秒數(shù)百萬條消息,同時保持毫秒級的延遲。
- 高可擴展性:通過增加Broker即可水平擴展集群,通過增加分區(qū)即可提升單個Topic的并行處理能力。擴容過程通常對服務(wù)影響較小。
- 持久化與高可靠性:消息被持久化到磁盤,并支持多副本(Replication)機制。即使部分節(jié)點失效,數(shù)據(jù)也不會丟失,服務(wù)仍可繼續(xù)。
- 高并發(fā)與容錯性:多個Consumer可以組成消費者組(Consumer Group),共同消費一個Topic,實現(xiàn)負載均衡和并行處理。消費者加入或離開組時,集群會自動進行重平衡(Rebalance)。
- 強大的流處理能力:Kafka不僅是一個消息隊列,其核心的Kafka Streams庫以及與之緊密集成的Kafka Connect,使其能夠構(gòu)建強大的實時流處理管道,進行數(shù)據(jù)的轉(zhuǎn)換、聚合和填充。
- 生態(tài)繁榮:Kafka與大數(shù)據(jù)生態(tài)(如Hadoop、Spark、Flink)結(jié)合緊密,是現(xiàn)代數(shù)據(jù)湖、數(shù)據(jù)倉庫中實時數(shù)據(jù)攝入的關(guān)鍵組件。
典型適用場景
基于其特性,Kafka在以下場景中表現(xiàn)尤為出色:
- 實時日志流收集與聚合:經(jīng)典的“日志中心”場景。各類應(yīng)用、服務(wù)將日志統(tǒng)一發(fā)布到Kafka,再由下游的日志檢索系統(tǒng)(如ELK)、監(jiān)控系統(tǒng)或數(shù)據(jù)倉庫進行消費和分析。
- 網(wǎng)站活動追蹤:記錄用戶的頁面瀏覽、點擊、搜索等行為事件,用于實時分析、個性化推薦或用戶行為建模。
- 消息驅(qū)動型微服務(wù)架構(gòu):作為微服務(wù)之間的異步通信總線,實現(xiàn)服務(wù)解耦、削峰填谷和最終一致性。例如,訂單服務(wù)產(chǎn)生訂單事件,庫存服務(wù)、物流服務(wù)異步訂閱并處理。
- 流式數(shù)據(jù)處理管道:作為實時數(shù)據(jù)管道,連接數(shù)據(jù)源與流處理引擎(如Flink、Spark Streaming)。例如,物聯(lián)網(wǎng)設(shè)備數(shù)據(jù)上報、金融交易實時風控。
- 事件溯源(Event Sourcing):將系統(tǒng)的狀態(tài)變化記錄為一系列不可變的事件,并存儲于Kafka。系統(tǒng)狀態(tài)可以通過重放事件來重建,為審計、調(diào)試和構(gòu)建衍生數(shù)據(jù)視圖提供了極大便利。
- 操作指標(Metrics)與監(jiān)控數(shù)據(jù)流:收集分布式系統(tǒng)中各節(jié)點的性能指標,進行實時監(jiān)控和告警。
###
Apache Kafka是一個為處理實時數(shù)據(jù)流而生的強大平臺。它并非一個簡單的“消息隊列”,而是一個分布式的、高可靠的、支持流處理的提交日志系統(tǒng)。企業(yè)在引入Kafka時,需充分權(quán)衡其帶來的高性能、解耦能力與隨之增長的架構(gòu)和運維復雜度。對于需要處理海量實時數(shù)據(jù)、構(gòu)建松耦合、可擴展的現(xiàn)代分布式系統(tǒng)的場景,Kafka無疑是一個經(jīng)過大規(guī)模實踐驗證的卓越選擇。理解其痛點、善用其優(yōu)勢,方能使其在企業(yè)的技術(shù)架構(gòu)中發(fā)揮最大價值。
如若轉(zhuǎn)載,請注明出處:http://m.hhpk1.cn/product/9.html
更新時間:2026-06-19 15:03:02